
Most developers using AI tools for coding skip the thinking part. They type a problem, hit enter, and expect perfect code to pop out. It doesn’t work like that. Not anymore. The real breakthrough isn’t in writing better prompts-it’s in making the AI explain itself first. That’s the core of Chain-of-Thought (CoT) prompting in coding: explanations before implementations.
Before 2022, large language models struggled with even simple algorithmic problems. A model might get a math word problem right 18% of the time. Then Google Research published a paper that changed everything. They didn’t retrain models. They didn’t add new layers. They just asked the AI to say: "Let’s think step by step." Suddenly, accuracy jumped to 79%. That’s not a tweak. That’s a revolution.
How Chain-of-Thought Actually Works in Code
Chain-of-Thought isn’t magic. It’s structure. When you ask an AI to code something complex-like implementing a dynamic programming solution for knapsack problems-it doesn’t just guess. It breaks the problem down. First, it restates what you’re asking. Then it asks: "What’s the input? What’s the output? What constraints exist?" Then it walks through possible approaches: "Option A is O(n²) but handles edge cases cleanly. Option B is faster but fails on negative values. I’ll go with A." Finally, it writes the code.
This isn’t just fluff. DataCamp tracked 1,200 GitHub repos and found that developers using CoT had 63% fewer logical errors in their first code draft. Why? Because the model caught its own mistakes before writing a single line. It spotted a loop that would run infinitely. It noticed a missing base case. It flagged a race condition. All before the code was generated.
Why Direct Code Generation Fails
Try this: Ask an AI to "write a function that finds the second largest number in an array." Most models will spit out code. But if the array has duplicates? Or is empty? Or has only one unique value? The code breaks. And you won’t know why until you test it.
Now ask: "Explain how to find the second largest number in an array, step by step." Suddenly, the AI says: "First, check if the array has at least two distinct values. If not, return null. Then, track the highest and second-highest as we iterate. Skip duplicates. Update values carefully." That’s not just code. That’s a safety net.
Google’s MultiArith dataset showed a 61-point improvement in accuracy just by adding "Let’s think step by step." The same pattern holds for real-world code. Junior devs using CoT cut debugging time by nearly half. Senior devs say they spend less time fixing edge cases because the AI already thought of them.
The Hidden Cost: Tokens, Time, and False Confidence
There’s a catch. CoT uses more tokens. GitHub’s data shows average requests jumped from 150 to 420 tokens. That means slower responses and higher costs. At scale, that adds up. One DevOps engineer on Hacker News calculated his monthly API bill went up 22% after switching fully to CoT.
And here’s the dangerous part: sometimes the explanation sounds perfect-even when it’s wrong. Dr. Emily M. Bender’s research found that 18% of CoT-generated reasoning steps were logically flawed but still led to correct code. Imagine a developer reading: "We sort the array and pick index -2. This works because..." and trusting it. The code runs. The tests pass. But the logic is brittle. If the array changes size? It crashes. And no one notices until production.
This isn’t a flaw in CoT. It’s a flaw in how we use it. We treat the explanation like gospel. We don’t question it. We should.

When to Use It (and When to Skip It)
CoT isn’t for everything. Don’t use it for boilerplate. Don’t use it for CRUD endpoints. Don’t use it for a simple React component. It’s overkill. The extra 15-20 seconds of thinking time? Wasted.
Use it when:
- You’re solving a dynamic programming problem
- You’re implementing a graph algorithm
- You’re handling edge cases like null inputs, race conditions, or floating-point precision
- You’re writing system design code (APIs, caching layers, retry logic)
- You’re on a team where code quality matters more than speed
Studies from Gartner and Forrester show that 94% of financial tech teams use CoT for trading algorithms. 92% of autonomous vehicle software teams use it for sensor fusion logic. Why? Because one wrong step can cost millions. In those fields, the extra time and cost aren’t a burden-they’re insurance.
How to Do It Right
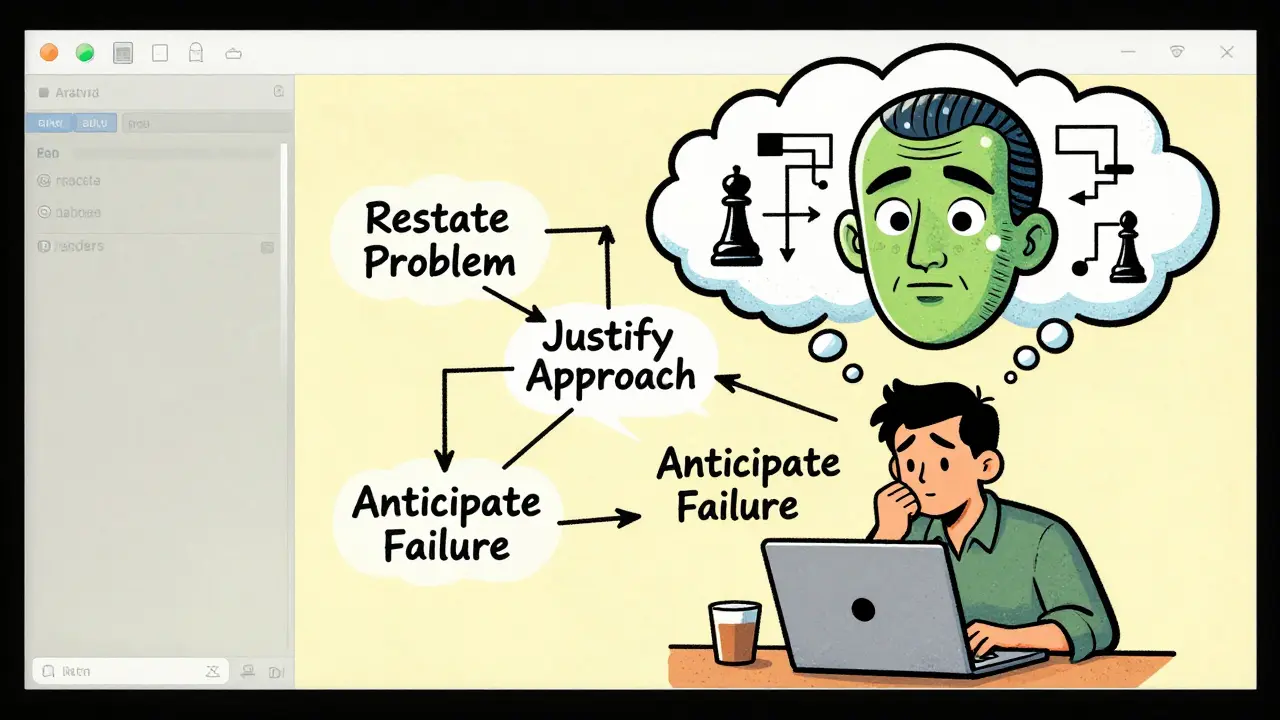
You can’t just type "think step by step" and call it a day. Effective CoT prompting has three parts:
- Restate the problem. Make sure the AI understands what you’re asking. "You need to write a function that returns the median of a sorted array. Correct?"
- Justify the approach. "Why use binary search here instead of linear scan? What’s the time complexity trade-off?"
- Anticipate failure. "What happens if the array has 0 elements? One element? All identical values?"
GitHub’s internal training program found that developers who followed this pattern reduced their AI-generated code errors from 34% to 12% in six weeks. The key? Practice. It takes 2-3 weeks to get good at crafting these prompts. You’ll suck at first. That’s normal.
And don’t rely on tools to do it for you. OpenAI’s GPT-4.5 now auto-applies CoT. That’s great-but it’s also risky. You don’t see the reasoning. You can’t audit it. You’re back to blind trust.
The Future: Auto-CoT and IDE Integration
The next wave is automatic. Auto-CoT, introduced in 2023, lets models generate their own reasoning steps without you prompting them. GitHub’s tests showed a 28% improvement in handling novel coding challenges. That’s huge.
And now, IDEs are catching up. JetBrains announced native CoT support in its 2025 lineup. Imagine typing a comment like "// find the longest increasing subsequence" and seeing a sidebar pop up with step-by-step reasoning before the code auto-fills. That’s not sci-fi. It’s coming.
But here’s the warning: if we stop thinking ourselves, we’ll stop learning. AI won’t replace developers. But developers who stop questioning AI reasoning? They will.
Final Thought: Don’t Just Ask for Code. Ask for Thinking.
Chain-of-Thought isn’t about getting better code faster. It’s about building better judgment. When you force the AI to explain itself, you’re forced to think too. You start spotting flaws in its logic. You learn why certain algorithms work. You understand the trade-offs.
That’s the real value. Not the code it writes. The understanding it builds.
Does Chain-of-Thought prompting work with all AI coding tools?
Not equally. Tools based on models with over 100 billion parameters-like GPT-4, Claude 3, and Llama 3-show strong results. Smaller models (under 10B parameters) rarely benefit. Most commercial AI coding assistants now include CoT as a default feature, but you should test it with your specific tool. If the AI gives vague or inconsistent reasoning steps, it’s not ready for CoT yet.
Can Chain-of-Thought replace code reviews?
No. CoT reduces errors, but it doesn’t eliminate them. Human review is still essential. In fact, CoT makes code reviews more effective because reviewers can now focus on logic gaps, not syntax errors. The AI handles the low-level mistakes; humans handle the high-level design.
Is Chain-of-Thought prompting expensive?
Yes, at scale. CoT prompts use 2-3x more tokens than direct code requests. For individual developers, the cost is negligible. For enterprise teams running thousands of AI-assisted requests daily, it adds up. But many teams report a net savings: fewer bugs, fewer code review cycles, less debugging time. The trade-off usually pays off.
Do I need to learn a new prompt format?
No. The simplest prompt is: "Explain how to solve this step by step, then write the code." You don’t need templates. But for complex problems, use the three-part structure: restate, justify, anticipate. That’s the sweet spot.
What if the AI’s explanation is wrong but the code works?
That’s a red flag. If the reasoning is flawed but the output is correct, you’ve got a ticking time bomb. The code might break under new inputs, edge cases, or refactoring. Always verify the logic. Don’t trust the output just because it passes tests. The explanation is your safety check.
Is Chain-of-Thought the same as "thinking aloud" in pair programming?
Yes, in spirit. Pair programming works because the developer verbalizes their thought process, catching mistakes before they’re written. CoT prompting mimics that. The AI is your silent pair programmer, explaining its reasoning aloud. That’s why it works so well-it replicates human cognitive patterns.





9 Comments
Aryan Jain
they dont want you to know this but ai is already writing your thoughts before you think them. chain-of-thought? more like chain-of-control. they trained it to sound smart so youll trust it more. next thing you know, your code runs but your mind is on vacation. wake up. this isnt progress. its a trap. 🤖
Nalini Venugopal
OMG YES!! 😍 I just started using CoT last week and my code is so much cleaner!! I used to get so frustrated when the AI would give me broken code, but now I actually read the steps first and it’s like having a super patient tutor. No more debugging for hours!! Thank you for this post!! 💖
Pramod Usdadiya
really like this post. i never thought about how ai explains things before coding. i just copy paste. but now i try to ask it to break it down. small change, big difference. my team noticed too. we had less meetings about bugs. thanks for sharing. 😊
Aditya Singh Bisht
Bro this is the game-changer I didn’t know I needed! 🚀 I was skeptical at first - thought it was just fluff - but after using CoT on a knapsack problem last week? I caught a logic flaw in the AI’s own reasoning BEFORE it wrote code. That’s wild. Now I use it for everything complex. It’s not about the code - it’s about learning how to think with the AI. You’re not replacing your brain, you’re upgrading it. Keep going, keep learning!
Agni Saucedo Medel
Yessss this!! 🙌 I use CoT for every single algorithm now. Even if it takes 5 extra seconds, I feel so much more confident. And the best part? My juniors are learning way faster because they can see the reasoning. It’s like teaching them to fish instead of giving them fish. 🐟✨
ANAND BHUSHAN
CoT works. But the token cost is real. My company’s bill jumped 30%. I still use it for complex stuff. Not for CRUD. Simple as that.
Indi s
thanks for this. i was just using ai to get code fast. didnt think about the thinking part. now i ask it to explain first. feels better. like i’m not just copying. i’m learning. small steps.
Rohit Sen
CoT? Cute. Real devs write code, not essays. If your AI needs a 400-token lecture to generate a sort function, you’re doing it wrong.
Vimal Kumar
Hey Rohit - I get where you’re coming from, but CoT isn’t about writing essays. It’s about catching mistakes before they become bugs. I used to be skeptical too - until I had a junior dev ship a production bug because the AI gave clean code but wrong logic. Now we always ask for the steps. It’s not slower - it’s smarter. And yeah, we still do code reviews. CoT just makes them way more meaningful. 💪