
Imagine asking your assistant to look at a photo of a broken engine part, listen to the grinding noise it makes, and read the error code on the dashboard-all in one go. You want an answer before you even finish speaking. That is the promise of Real-Time Multimodal Assistants powered by Large Language Models (LLMs). These systems don't just chat; they see, hear, and understand simultaneously with near-zero delay.
We are no longer waiting for the future. As of mid-2026, these tools have moved from experimental labs into customer service centers, hospitals, and classrooms. But how do they actually work under the hood? And more importantly, are they ready for your specific use case without breaking your budget or frustrating your users?
What Makes an Assistant "Multimodal" and "Real-Time"?
To understand the hype, we need to strip away the marketing jargon. A standard Large Language Model (LLM) like early versions of GPT handled text. It was brilliant at writing emails but blind to images and deaf to audio. A Multimodal Large Language Model (MLLM), as defined by NVIDIA’s glossary, processes various forms of content-text, images, video, and audio-simultaneously.
The "real-time" aspect is the game-changer. In older systems, you would upload an image, wait for processing, then type a question. With real-time assistants, the interaction flows like a natural conversation. The system ingests data streams, fuses them together, and generates a response often within milliseconds. Google’s Gemini, introduced in late 2023, set the stage by demonstrating sub-second response times for standard queries. Since then, the bar has been raised significantly.
Why does this matter? Because human conversation relies on immediate feedback. If an AI pauses for five seconds to "think" about what it sees, the illusion of intelligence breaks. Real-time processing keeps the user engaged and allows for dynamic, context-aware interactions that static models simply cannot match.
The Core Architecture: How It All Fits Together
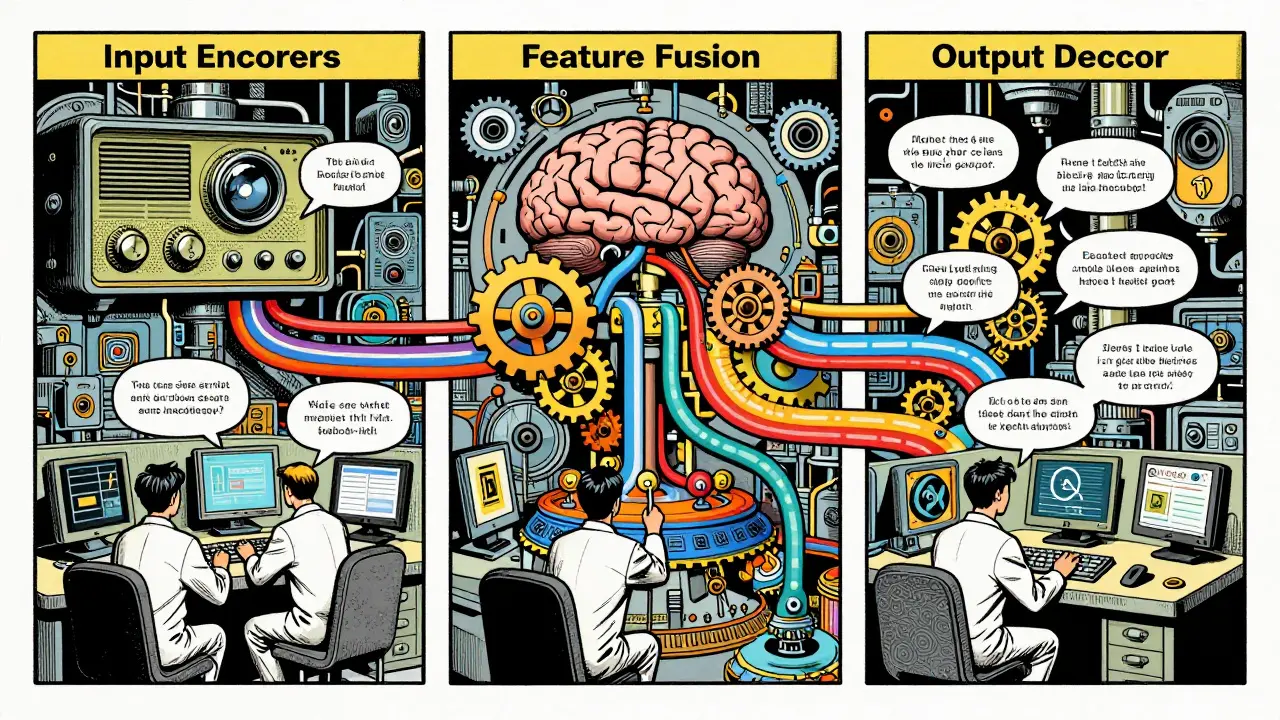
You might wonder how a single model handles such diverse inputs. The architecture typically consists of three critical components working in tandem:
- Multimodal Input Encoders: These are specialized modules that translate raw data into a format the LLM understands. For example, a module like CLIP-ViT processes images, while other encoders handle audio waveforms or video frames. They act as translators, turning pixels and sound waves into mathematical vectors.
- Feature Fusion Mechanisms: This is the brain’s integration center. It takes the translated data from different modalities and merges them. The MM-Interleaved framework, detailed in a 2024 arXiv review, uses a Perceiver Resampler to map images into visual tokens that the LLM can digest alongside text tokens.
- Multimodal Output Decoders: Finally, the system generates a response. This could be text, speech, or even a modified image. The decoder ensures the output matches the complexity and modality of the input.
This unified approach is crucial. Older "cascaded" methods used separate models for each task-sending data from one model to another-which led to significant information loss. According to the Lamarr Institute blog (January 2025), cascaded approaches suffered an 18.7% error rate during modality translation. Unified architectures like those in GPT-4o reduced this error rate to just 5.2%, making the interactions far more reliable.
Performance Benchmarks: Speed vs. Accuracy
Speed is everything in real-time applications. But faster isn't always better if it means sacrificing accuracy. Let's look at the numbers from MLPerf Inference 4.0 (June 2025) and Stanford HELM benchmarks (April 2025).
| Model | Text Latency | Image Latency | Audio Latency | Multimodal Accuracy |
|---|---|---|---|---|
| GPT-4o | 120ms | 450ms | 300ms | 91.3% |
| Gemini 1.5 Pro | 180ms | 500ms | 350ms | 89.5% |
| Llama 3 Multimodal | 280ms | 650ms | 500ms | 87.1% |
GPT-4o currently leads in pure speed, particularly for text and audio. However, Gemini 1.5 Pro shines in video processing, handling complex temporal sequences better than its competitors. Meta’s Llama 3 offers strong open-source flexibility but lags in raw real-time performance, which matters less for batch processing but critically for live interactions.
There is a trade-off here. The arXiv comprehensive review (August 2024) noted that real-time implementations sacrifice 7-12% accuracy compared to non-real-time models to achieve speed. For a casual chatbot, this is fine. For a medical diagnostic tool, it’s a major concern.
Infrastructure Requirements: What You Need to Run Them
If you’re thinking of deploying these assistants, prepare your wallet and your server room. Real-time multimodal processing is computationally expensive. It requires substantial power to maintain low latency.
For consumer-grade implementations, you need at least 24GB of VRAM. But for enterprise environments handling heavy loads, you’re looking at distributed GPU clusters. Typical setups involve 4-8 NVIDIA A100 GPUs to keep response times under one second. The computational demand is roughly 15-20 TFLOPS for real-time operation.
Hardware evolution is helping. NVIDIA’s Blackwell Ultra architecture, launched in January 2025, reduced multimodal processing latency by 40% compared to previous generations. Still, the cost remains high. Enterprise licenses for on-premises solutions start at $250,000 annually. Cloud-based APIs offer a cheaper entry point, with GPT-4o charging around $0.0015 per text token and $0.012 per image token (as of June 2025 pricing).
Developers also face a steep learning curve. Stack Overflow’s 2025 Developer Survey reported that it takes 8-12 weeks to achieve proficiency. You’ll need skills in PyTorch or TensorFlow (used in 92% of implementations), CUDA optimization (67%), and multimodal data pipeline management (84%).
Where Are They Used? Real-World Applications
So, who is using this technology right now? The market is growing fast, projected to reach $22.6 billion by 2027. Here are the top sectors:
- Customer Service: This is the biggest adopter. Zendesk’s 2025 report showed that real-time multimodal assistants reduce resolution time by 47%. Agents can see a customer’s screen, hear their frustration, and read chat logs simultaneously, providing instant, contextual help.
- Healthcare Diagnostics: Doctors use these tools to analyze patient symptoms described verbally, combined with medical images (X-rays, MRIs). However, caution is advised. Professor Yoshua Bengio warned about the "illusion of understanding," where models generate coherent responses without true comprehension-a dangerous flaw in critical care.
- Education: MIT’s 2024 study found a 38.2% improvement in student engagement when using multimodal tutors. These assistants can explain complex diagrams while listening to students’ questions, adapting their teaching style in real-time.
- Accessibility: For users with visual or hearing impairments, these assistants provide real-time captioning, audio descriptions of surroundings, and sign language interpretation, bridging communication gaps instantly.
Despite the benefits, limitations exist. Complex video understanding tasks requiring temporal reasoning still struggle, with accuracy dropping to 62.4% on the Video-QA benchmark. Systems also face challenges with highly specialized domain knowledge requiring precise visual analysis.

User Experience: The Good, The Bad, and The Latent
Technology only works if people like using it. User feedback paints a mixed picture. On G2, real-time multimodal assistants average 4.2 out of 5 stars. Sixty-eight percent of reviewers praise the contextual understanding. But 42% cite inconsistent performance across different modalities.
Latency is the make-or-break factor. Enterprise users on Capterra identified an "800ms threshold." If the assistant takes longer than 800 milliseconds to respond, user dissatisfaction jumps by 63%. Anything over a second feels sluggish in a conversational interface.
Synchronization issues are another pain point. Thirty-one percent of complaints on HackerNews in early 2025 described "jarring transitions between modalities." Imagine describing a car crash while the AI analyzes the video feed-if the audio and video processing aren’t perfectly synced, the advice given can be dangerously outdated or irrelevant.
The Future: Where Is This Heading?
We are at the "Peak of Inflated Expectations" according to Gartner’s 2025 Hype Cycle. Analysts predict 2-5 years before mainstream enterprise adoption becomes cost-effective outside of tech giants. However, the trajectory is clear.
Google’s Project Astra aims for sub-100ms multimodal processing by late 2025. OpenAI is rumored to be developing a next-generation architecture expected later this year. Meanwhile, open-source communities are pushing boundaries with projects like LLaVA-Next, which has gained over 28,000 GitHub stars.
Three key trends will shape the next few years:
- Hardware-Software Co-Design: Chips will be built specifically for multimodal fusion, reducing latency further.
- Standardized APIs: The W3C working group established in November 2024 is working on standardizing multimodal interfaces, making integration easier for developers.
- Vertical Specialization: Instead of general-purpose assistants, we’ll see specialized tools for law, medicine, and engineering, trained on domain-specific multimodal data.
Regulatory frameworks are also catching up. The EU’s AI Act, effective January 2025, requires multimodal systems processing biometric data to undergo stringent real-time accuracy testing, with a minimum 85% threshold. This ensures that as these tools become more powerful, they remain safe and accountable.
Real-time multimodal assistants are not just a novelty; they are becoming the new standard for human-AI interaction. While challenges in cost, consistency, and synchronization remain, the rapid advancements in hardware and model architecture suggest that seamless, multi-sensory AI assistance is closer than ever.
What is the difference between a standard LLM and a Multimodal LLM?
A standard Large Language Model (LLM) primarily processes and generates text. A Multimodal Large Language Model (MLLM) can process and integrate multiple types of data, including text, images, audio, and video, allowing for richer, more context-aware interactions.
How much hardware do I need to run a real-time multimodal assistant?
For basic consumer-grade implementations, you need at least 24GB of VRAM. For enterprise-level performance with sub-second latency under heavy load, you typically need a cluster of 4-8 NVIDIA A100 GPUs or newer equivalents like the Blackwell Ultra architecture.
Are real-time multimodal assistants accurate enough for medical use?
They show promise but come with risks. While they can assist in diagnostics, experts warn of the "illusion of understanding." Current systems may sacrifice 7-12% accuracy for speed. Regulatory bodies like the EU require strict accuracy thresholds (minimum 85%) for biometric and critical decision-making applications.
What is the acceptable latency for a real-time AI assistant?
User experience studies indicate an 800-millisecond threshold. Responses faster than this feel natural. Delays exceeding 800ms lead to a 63% increase in user dissatisfaction, as the interaction no longer feels "real-time" or conversational.
Which companies lead the market in multimodal AI?
As of 2026, Google, OpenAI, and Meta dominate the landscape, controlling approximately 74% of the market. Google’s Gemini and OpenAI’s GPT-4o are leading in proprietary solutions, while Meta’s Llama 3 variants lead in open-source flexibility.
How much does it cost to implement these systems?
Costs vary widely. Cloud API usage for models like GPT-4o starts around $0.0015 per text token. On-premises enterprise licenses can exceed $250,000 annually due to the required GPU infrastructure and maintenance costs.
What are the main technical challenges in building these assistants?
Key challenges include managing variable input latencies (text arrives faster than processed images), ensuring temporal synchronization between audio and video streams, and maintaining high accuracy across all modalities without excessive computational overhead.
Is the market for multimodal AI growing?
Yes, rapidly. The global multimodal AI market is projected to grow from $4.2 billion in 2024 to $22.6 billion by 2027, with a Compound Annual Growth Rate (CAGR) of 34.7%. Real-time implementations account for 68% of this growth.
Can open-source models compete with proprietary ones?
Open-source models like Llama 3 and LLaVA-Next offer greater flexibility and lower licensing costs. However, they currently lag behind proprietary leaders like GPT-4o and Gemini in raw real-time performance and ease of integration, though the gap is narrowing quickly.
What regulations affect multimodal AI deployment?
The EU’s AI Act (effective January 2025) imposes strict requirements on systems processing biometric data, mandating real-time accuracy tests with a minimum 85% pass rate. Other regions are developing similar frameworks to ensure safety and transparency in AI interactions.




