
Imagine handing the keys to your entire company database to a brilliant but unpredictable intern. That is essentially what happens when you integrate a Large Language Model (LLM) into your business without strict boundaries. These models are powerful tools for generating text, analyzing data, and automating tasks, but they do not understand corporate hierarchy or data sensitivity. If an attacker tricks the model into revealing customer records, or if the model hallucinates sensitive internal metrics, the damage can be severe.
This is why traditional perimeter security-like firewalls that protect the outside edge of your network-is no longer enough. You need a different approach. Zero-Trust Architecture (ZTA) operates on one simple rule: never trust, always verify. In the context of AI, this means treating every request from an LLM as potentially hostile until it is proven safe. It assumes that threats exist both inside and outside your network, and it verifies every interaction before granting access to data or systems.
The Core Principles of Zero Trust for AI
Adapting Zero-Trust Architecture for Large Language Models requires more than just standard IT security practices. You have to account for the unique way AI processes information. The Cloud Security Alliance highlights four critical capabilities that form the backbone of this strategy.
First, you must enforce strict access controls. This follows the principle of least privilege. An LLM should only see the specific data it needs to perform a task at that exact moment. If a chatbot helps with HR questions, it should not have access to financial spreadsheets. Second, continuous monitoring is essential. You cannot set up rules and walk away. Advanced analytics must watch for anomalous behavior in real-time, such as sudden spikes in data requests or unusual outputs that might indicate a breach attempt.
Third, strong data protection mechanisms like encryption and segmentation keep sensitive information safe throughout its lifecycle. Finally, behavioral baselining helps identify what "normal" looks like for your AI systems. When the model deviates from this baseline, the system can flag the activity for review or block it entirely. The National Institute of Standards and Technology (NIST) recommends implementing microsegmentation policies that allow only business-required communication between systems, further reducing the attack surface.
Securing Data Pipelines and Training
Data pipelines are the foundation of any AI system, and they are often the weakest link in security. To implement zero trust here, organizations rely on three advanced techniques: differential privacy, homomorphic encryption, and secure enclaves.
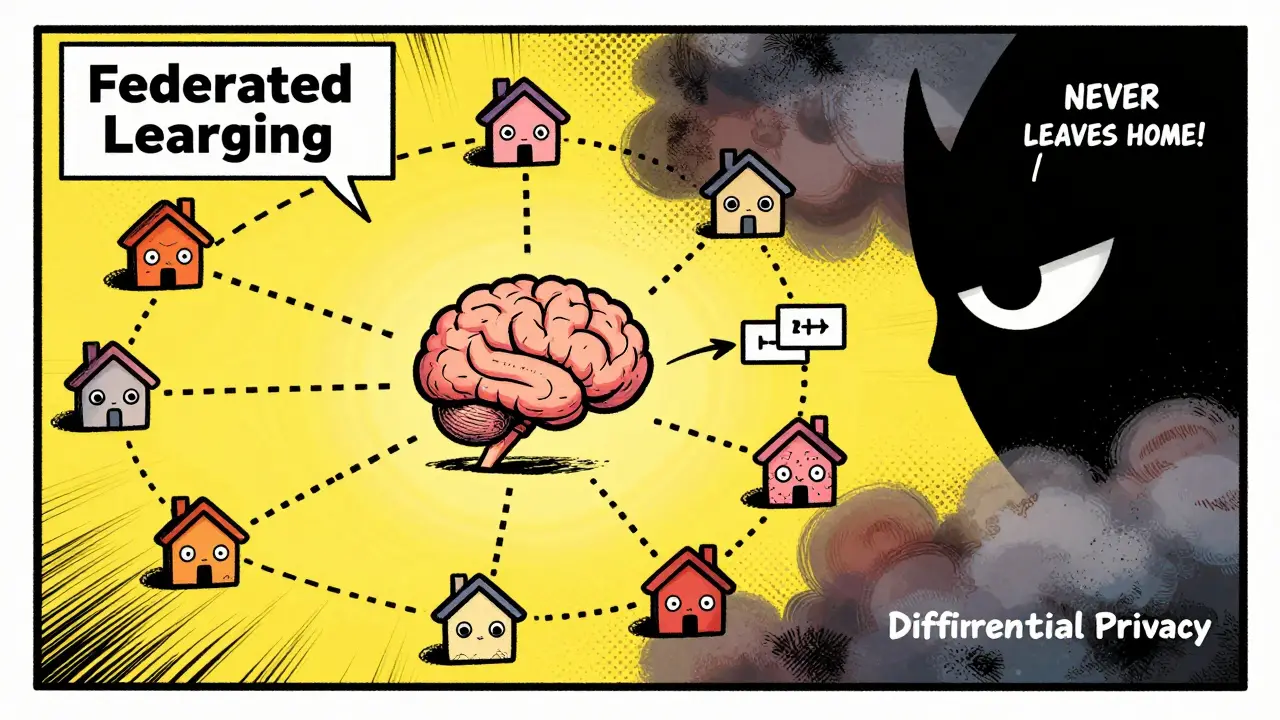
- Differential Privacy: This technique adds statistical noise to datasets. It allows the model to learn general patterns without memorizing specific individual records. If someone tries to reverse-engineer the data from the model's output, they will find only generalized trends, not private details.
- Homomorphic Encryption: This allows computations to be performed on encrypted data without decrypting it first. The model can process the information and return results, all while the underlying data remains unreadable to anyone who might intercept it.
- Secure Enclaves: These are isolated areas of memory within a processor. They provide a trusted execution environment where sensitive code and data can be processed safely, protected even from the operating system or other applications running on the same machine.
Another powerful method is Federated Learning. Instead of sending all raw data to a central server for training, federated learning keeps data decentralized. The model travels to the data, learns from it locally, and then sends back only the model updates. This significantly reduces privacy risks because the raw sensitive information never leaves its original location. However, you must still guard against attacks like model inversion, where attackers try to reconstruct input data from the model updates.

Practical Implementation in RAG Systems
Many enterprises use Retrieval-Augmented Generation (RAG) systems to give LLMs access to proprietary knowledge. A RAG system retrieves relevant documents from a vector store and feeds them to the model to generate a response. Securing this flow is critical.
Consider a practical example using a PostgreSQL vector store. To apply zero trust principles, you would limit access to vector tables via role-based controls. Only authorized services can query the database. You would also mask sensitive fields, such as document titles containing customer names, so the LLM sees redacted versions unless explicitly permitted otherwise. Every embedding lookup and prompt input must be audited. If you notice an unusual volume of queries targeting specific sensitive topics, your system should trigger an alert or block the activity immediately.
This approach uses database-level masking policies to automatically hide sensitive information from the LLM access layer. It ensures that even if the model is tricked into asking for private data, the infrastructure prevents it from receiving the full picture.
Technical vs. Topic Interactions
A crucial distinction in securing LLMs involves two separate dimensions: technical interactions and topic interactions. Technical interactions refer to what systems the model can call and what data it can access. Topic interactions are much harder to control because they deal with what subjects the model discusses.
System guardrails act as the first line of defense for topic interactions. They perform broad restrictions by preventing unsupported languages, identifying attempts to make inappropriate interactions, and rejecting responses that include private information or intellectual property leakage. For example, a guardrail might detect that a user is trying to extract trade secrets through a series of cleverly phrased questions and block the response before it reaches the user.
The Zero-Trust Decision Context principle states that when a model makes a request, the context provided should be limited strictly to what is required for that specific response. Imagine an airline rebooking bot. It should only receive the relevant flight plans, available seats, and current reservations of affected passengers. It should not have access to the entire vector database of customer history. Limiting context reduces the risk of accidental data exposure.
The Sentinel System and Continuous Monitoring
To truly enforce zero trust, you need a sentinel system. This is a fully separated solution that accompanies the model with the specific goal of looking for anomalous behavior. Unlike passive monitoring tools, a sentinel actively approves every request for resources that the model makes.
This sentinel is part of a broader Trusted AI framework designed to constrain the AI system within its digital contracts and responsibilities. It has the authority to take the AI offline if security thresholds are exceeded. This represents a fundamental shift from traditional security models. In the past, monitoring was reactive; now, it must be proactive and interventionist.
Advanced anomaly detection systems employ techniques such as isolation forests or autoencoders to identify outliers in high-dimensional spaces typical of AI data. These tools help detect deviations from expected behavior, ensuring that the model is being used as intended and in alignment with ethical guidelines.

Organizational Culture and Policy
Technology alone cannot solve security challenges. Implementing zero trust for AI-native workloads requires a holistic organizational approach encompassing people, processes, and technology. Employees must be trained on security best practices specific to AI. They need to understand how to handle prompts responsibly and recognize potential social engineering attacks aimed at manipulating the model.
Clear policies and procedures for handling AI workloads are essential. Organizations should invest in zero trust solutions specifically designed for AI and LLMs rather than attempting to adapt generic security platforms. Generic tools often lack the depth needed to understand semantic nuances and complex model behaviors.
| Feature | Traditional Perimeter Security | Zero-Trust for LLMs |
|---|---|---|
| Trust Assumption | Trusts internal users and devices | Never trusts, always verifies |
| Access Control | Role-based, static permissions | Attribute-based, dynamic, least privilege |
| Monitoring | Reactive, log-based | Proactive, real-time behavioral analysis |
| Data Protection | Encryption at rest and in transit | Encryption, masking, differential privacy, homomorphic encryption |
| Response to Threats | Block after detection | Preventive blocking, active approval of requests |
Challenges and Future Outlook
Implementing zero trust for LLMs is not without its difficulties. One major challenge is that the feature list of LLMs is largely unknowable due to their complex nature. Because these models are probabilistic and non-deterministic, predicting every possible output is nearly impossible. This makes complete zero trust enforcement inherently difficult.
The complexity of implementing system-level guardrails at the topic and feature level remains a significant practical hurdle. Balancing security constraints with model functionality requires careful calibration. Too many restrictions can degrade the user experience and reduce the usefulness of the AI. Too few can lead to security breaches.
Despite these challenges, the field is maturing rapidly. Industry experts recognize that while technical access controls are challenging but achievable, semantic-level control of LLM behavior through guardrails and filtering mechanisms presents a more complex problem requiring continued development. As we move through 2026, organizations are increasingly adopting hybrid approaches that combine robust technical controls with human-in-the-loop oversight for high-risk decisions.
What is Zero-Trust Architecture in the context of LLMs?
Zero-Trust Architecture for LLMs is a security framework based on the principle of "never trust, always verify." It treats every user, device, and system interaction involving the Large Language Model as potentially hostile. Access to data and resources is granted only after rigorous verification, and permissions are limited to the minimum necessary for each specific task.
How does Federated Learning enhance data privacy?
Federated Learning enhances data privacy by keeping training data decentralized. Instead of sending raw sensitive data to a central server, the model is sent to the data source. It learns locally and sends back only the model updates. This ensures that private information never leaves its original environment, reducing the risk of data breaches during the training process.
What is the role of a sentinel system in LLM security?
A sentinel system is a dedicated security component that monitors an LLM's behavior in real-time. It actively approves every resource request made by the model and looks for anomalous behavior. If the model attempts to access unauthorized data or exhibits suspicious patterns, the sentinel can block the action or take the AI offline to prevent potential harm.
Why are traditional firewalls insufficient for protecting LLMs?
Traditional firewalls protect the perimeter of a network but do not monitor internal traffic or application-level interactions. LLMs often operate within distributed systems and access data dynamically. Attackers can exploit vulnerabilities inside the network or manipulate the model through prompts. Zero Trust addresses these internal threats by verifying every transaction regardless of its origin.
How can organizations implement differential privacy?
Organizations can implement differential privacy by adding statistical noise to datasets used for training or querying. This noise masks individual records while preserving overall statistical patterns. As a result, the LLM can learn general insights without memorizing specific private details, making it difficult for attackers to reverse-engineer sensitive information from the model's outputs.




